Chained Rows, Migrated Rows, Row Pieces – The Basics October 11, 2022
Posted by mwidlake in Architecture.Tags: internals, performance, SQL
trackback
For #JoelKallmanDay I wanted to go back to basics and remind people what Chained & Migrated rows are, and something about row pieces.

First, let’s review how an oracle block is structured. All tables and indexes are made of blocks and they are (by default) all the same size in a given database and the size is stated when you create the database. Blocks are usually 8K (the default), less often 16K and rarely can also be 2K, 4K, or 32K in size. If you want to use a block size other than 8K or 16K, please have a very good, proven reason why before doing so. You can create tablespaces with a block size different to the one stated at database creation, but again you should only do this if you have a very good, proven reason. And I mean a VERY good reason for this one!
(If you have gone the whole CDB/PDB route then PDBs have the same block size as the CDB. You *can* plug in PDBs with different block sizes but check out Mike Deitrich’s post on this first).
At the “top” of the block is the block header, which includes information and access control structures for the rows in the block. Unless you are using Direct Insert, rows are actually inserted from the bottom of the block” upwards, until there is only PCTFREE space available. This is the free space left to cope with row updates and defaults to 10%. PCTFREE is hardly changed these days, which is a shame as it can be very useful to change it for some tables – but that is a different topic.
Why would you use 16K rather than the default of 8K? it is usually used for Data Warehouse database or other database holding long rows. You will generally waste less space within the blocks and avoid row chaining (see later) by having larger blocks, but if you have short rows and an OLTP type database (where you read lots of individual rows) then 16K will be more wasteful of your buffer cache in the SGA and make less efficient use of that memory.

In the above, row 103 is updated, making the row longer. All the rows are packed together so to do this Oracle can do one of two things. In (1) there is enough space at the “top” of the block to hold the whole row, so it is simply moved there and the pointers in the header updated. If there is not enough space in the “top” of the block but there is within the whole block (2), then Oracle moves Row 3 to the “top” of the block and shuffles the rest.

However, if you update a row and there is not enough frees space in the block, what does Oracle do? It Migrates the row. It leaves the row header in the original location but that simply holds a pointer (a ROWID) to the new location of the row – which could be in a block a long way away from the original row, even in a different file of the tablespace. All the columns for the row are moved to this new location. As you are changing two blocks there will be even more REDO generated than if the updated row was contained in the PCTFREE area.
Why does Oracle leave the header in place and simply point to the new row location? Well, if the ROWID for the row changes (as it would if the block it is in changes) then if there any indexes referencing that column, those index entries would need to be changed. Also any internal-to-oracle use of ROWIDs would need to be managed. That is extra work for the database to do and it will take more time. Usually people want updates to happen as quickly as possible.
The impact of this is that if you select that row via eg an index, Oracle will find the row header and have to do a second single block read to get the actual row. That’s more (possibly physical) IO and two blocks in the buffer cache not one. So it is slower. Lot s and lots of row migration can slow down eg index ranges scans considerably.
The impact on full table scans of a simple Migrated row is pretty much zero. Oracle is scanning the full table, the actual row will be found in due course no matter where it is in the table (or partition). The header is simply thrown away.
(Note, if you have enabled ROW MOVEMENT for the table then the whole row may be moved and the relevant indexes/internal rowid references updated – but that’s an advanced topic).
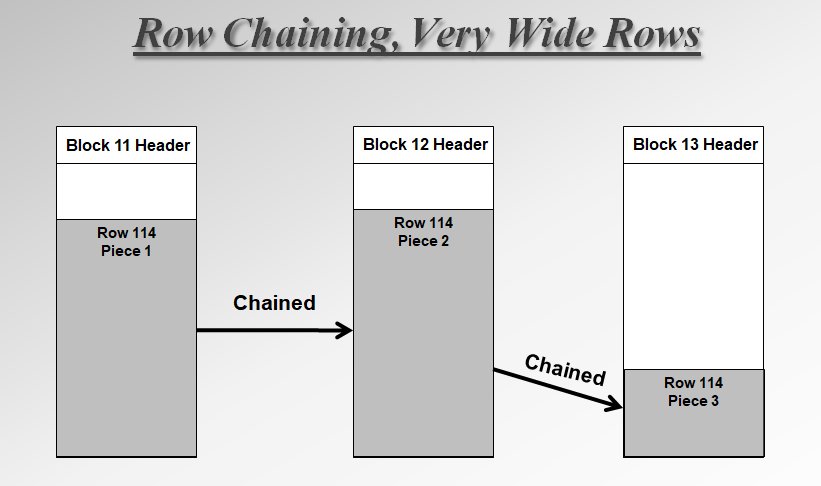
Row chaining is where a row is to wide to fit into a single block. In this case Oracle has no choice but to create several ROW PIECES. In reality every row consists of a header and ROW PIECE but there is only one and it is the ROW PIECE that is migrated with migrate rows. If the row is larger than the block then the row header and the first piece is put in the first available block. If the row is being created large then the next piece(s) are usually put in the following blocks.
Of course, the row could be absolutely massive and chained over many, many blocks. This is generally an indication that the table design and the physical implementation of the database has not been thought about enough and you should either learn enough to sort it out yourself or find someone who can help you with that, it could well help make your database run more efficiently. I’m retired, don’t come and ask me.
You can easily see that if you are reading this single row, for example via an index lookup, then Oracle is going to have to read as many blocks as the row spans. That’s more IO. This won’t happen if all the columns you want are in the first row piece though – Oracle will stop working through the row pieces once it has all the columns it needs.
This sort of row chaining where the row pieces are in contiguous blocks is not much of an issue during FTS as Oracle will stitch the pieces together in memory.
Of course, if you have updated the row to make it too large to fit in a block, your row may not only be chained but migrated, and the row pieces may not be contiguous, especially if you updated the row over several statements/period of time.

There can be even worse issues that come with tables with over 255 columns, but that would be for another blog.


Comments»
No comments yet — be the first.