Don’t Forget Old Features – Materialized Views #JoelKallmanDay October 11, 2023
Posted by mwidlake in Architecture, database design, development, Knowledge, performance, SQL.Tags: JoelKallmanDay, Materialized Views, performance, SQL, system development, user group
add a comment
People who spread knowledge on technical subjects tend to focus very much on the new, shiny features and enhancements. Maybe as a result of this, old features get forgotten about – like Table Clusters. How many of you know what Oralce Table Clusters are and how they might improve performance? Who has used Table Clusters in Oracle in the last 20 years? (Apart from everyone – as the data dictionary still uses them!). Table Clusters are maybe worth leaving in the past as, apart from the niche use of Single Table Hash Clusters to give a very efficient selection path for a row in a static table via the PK, they generally have more issues than benefits I think.
Well, an old feature I do think is worth revisiting is Materialized Views. This is where you create a real table based on a SQL query. The SQL query can be simple or complex, it can join two or more tables together, it can even group data and select min, max, avg, analytical funcitons etc to summaries large data sets.
Consider the below query:

A Materialized View can be created that does the main, expensive join and includes SOME of the filters:

This query iu run and the yellow “MV_BF_BD” table is physically created and populated. It is “Just” a table.
If the data in the underlying tables change, the Materialized View is marked as unusable and won’t be used. Used for what?
If the SQL statement used to create the Materialized View is a SQL statement the application uses or, more significantly, is a common part of several larger, more complex SQL statements, Oracle can use the Materialized View (which is just a table remember) to help satisfy the query.
In the below we see two SQL statements. One will certainly use the Materialized View and will, as a result, run more quickly. The second query might use the MV, the opitimizer will decide.

If this Materialized View takes a lot of time or resource to be generated (say it joins a million row table to a 100 millon row table and then filters out 50% of the joined rows) then by generating it once and then using the RESULTS only in half a dozen queries then it will make that half a dozen queries run faster.
I know I have not explained Materialized Views in enough detail to help you use them (though I might come out of retirement to write about them based on real world experience I had with one of my last clients), but that is not my point, it is just an example of something that can really help certain Oracle systems run more efficiently. But is hardly used anymore, possibly as it is old and not talked about much.
Just because an Oracle feature is old, it does not mean it is not still of use. How do you find out about these features? Well, I have a load of old performance and database design manuals I am throwing out that you could buy… 😄. Being serious, go have a look at the concepts manual. I used to always recommend all DBA-types and Oracle Developer types read the concepts manual for their version of Oracle. I still think it is a good idea (though I have not done it for a few years as, in my opinion, the manuals got a bit crap for a while – they seem better now). Alternatively, go to speak with someone really experienced (and thus probably quite old, but there are exceptions), describe the issue you have, and they might say something like “ohhh, that sounds like Results Cache could help – but be aware of these 3 terrible drawbacks of them”.
This post is in honour of Joel Kallman, who was a tireless advocate of learning & community. Just like him, I think the more we share our knowledge and help each other, the better we will all become.
On Watching “Task Master” Being Recorded April 11, 2023
Posted by mwidlake in off-topic, Private Life, TV.Tags: Humour, perception, performance
add a comment
Being semi-retired has allowed Sue and I to occasionally go to recordings of TV and radio programs. Last September we went off to see an episode of “Task Master” be recorded over in Pinewood studios. Task Master is very popular in the UK and many countries either show it or have made their own version. Basically, the hosts (Task Master Greg Davies, and assistant Alex Horne – who actually created the show) set a panel of 5 comedians daft tasks to complete and the Task Master awards points to them for how well they did. It is funniest when the contestants either make a complete mess of the task, or they fall out over the scoring. I’ll let you in on one thing about the episode we saw being recorded. If they show even half of the initial prize task it will be brilliant.

We did not realise this when we turned up but we were not seeing the recording of the series that was running on TV at that time – series 14 with Dara O’Brien & Sarah Millican – but series 15 with Frankie Boyle, Ivo Graham, Jenny Eclair, Kiell Smith-Bynoe, and Mae Martin that is being broadcast right now. We knew the tasks were recorded many months before being shown (the weather/season gives that away!) but not that the screenings were recorded a good 6 months before airing too.
It’s very interesting watching a TV program being recorded. If you ever get the chance, go and do so. It’s generally free to be in the TV audience in the UK but actually getting into the audience of something as popular as Task Master is a bit of a… task (see what I did there). You send in a request for a screening and a lucky few get selected.
One of the first things that strikes you is, it’s incredibly fake. As in the set is incredibly fake. Task Master looks like it is recorded in a theatre and, to be candid, we assumed it was – even though we had seen a couple of other programs recorded and knew the studio was usually a large, tatty hanger of a building with dirty floors and piles of odd (and sometimes bizarre) things in the corners & sides. Task Master is recorded in just such a barn, with the carefully constructed and far more polished set sitting somewhat incongruously in the centre of it. The cameras are of course angled to only show the nicely presented set and not the riot of panels, cables, equipment, abandoned furniture etc that starts less than half a meter from in-shot.
When the cameras pan to audience you don’t really notice that they are sat on the sort of chairs you find in church halls up and down the country or they are up on scaffolding (literally, scaffolding) which wobbles a bit as people get up or down from it en masse at the start & end of recording. The decoration on the fake balconies sat in by some of the audience and the thrones Greg and Alex sit on is pretty crude, but then there would be no point making it any finer as the resolution of the TV image would hardly pick it out – and you don’t really stare at the set.
We were fortunate in being sat on the second row from the front (being as short as we are, our view is easily obscured) and as we were lower than the stage and screen, we could see everything with no obstruction. What really did surprise me was how close to the stage we were. The person in front of me could have remained sitting and yet still be able to reach out and slap Frankie Boyle on the knee. She didn’t.
Comedy shows have a warm up act, to get you in the mood, and we had Mark Olver. He warms up for a few of the well known comedy panel programs and he’s very good. Of course, as his material is not shown he can recycle his stuff for different audiences, but he does not do the same set each time. Greg came out a few minutes before we started recording and joined in with the warm up . Even though Task Master is recorded (not live like “The Last Leg”, which Mark also warms up for) they still have the breaks where, when you watch the program, they go to the ads. Mark keeps you entertained during them and actually Greg and Alex join in a little. It also gives you an opportunity to stand up for a few minutes, those church hall chairs are damned uncomfortable after an hour or so.
Sue particularly enjoyed this recording as she soon realised that Greg Davies had taken a shine to her. It would be an odd pairing, Greg is well in excess of 1.5 foot (1/2 a meter) taller than Sue. But true love will find a way. Greg would look around at the contestants, the audience, Alex, but he kept coming back to look at Sue. And he smiled at her. A lot. At times it was like she was the only person in the audience for him and he was mesmerised by her. He talked straight at her, especially if he was doing quite a long bit if prepared stuff.
Yeah, she had the autocue right behind her and she had not realised.
Talking of autocue, obviously some bits of the program are scripted, quite a bit of what is said direct to camera is, but the banter between the boys at the start is not (well, I think the first line for Alex might be but not the rest) or the discussion with the panel of contestants. All that discussion of the tasks seems genuinely in-the-moment from the the contestants, Greg has some notes but he often seems to forget all about them. And the contestants do not know what tasks are about to be put up on the screen. I distinctly heard Ivo say to Jenny something like “Oh God, not this one!” and she replied something like “Which one is… {pained} ahhh…”.
The time spent recording the program is about two times as long as the program as shown, maybe more, but there is not a lot of wasted time. I think it is more making sure they have plenty of good material so that when they edit down to the program run time it is all good. I have no idea if the edition we saw being filmed was unusual or not but I think they had more than enough good stuff. Apart from Greg bolloxing up his lines all the time, but that will make for good outtakes. Having seen the first two broadcast editions and seen this one “in the flesh”, I think it is gong to be a very, very good series of Task Master,
I won’t say anything too specific about the content of the episode. You agree not to when you request tickets and this is repeated when you are there at the recording. Of course you cannot take photographs or record anything. Even if it would not get me banned from future TV audiences I would not say anything specific about the content before it goes out, that would be a bit of a dick thing to do. But…
- I’ll be very interested to see how much of Frankie’s introductory prize task item and the discussion about it gets into the final program. I would not be amazed if they had to cut 90% of it!
- The task with the potatoes is brilliant and the best part of it is Jenny.
- Ivo is very, very quick (meaning smart) with his comments.
- I get the feeling there is going to be quite some… friction over some of the scoring as the series progresses.
- My money is on Mae to win the series – but that does not indicate what happened in this episode.
Anyway, it was fascinating to see the process and I’m really looking forward to seeing “our” episode – and what does and does not make the edit.
***update*** – OK, seen the broadcast version. I thought 10% of Frankie Boyle’s “heroic thing” would get in. I was wrong, it was about 2%! A totally pixelated picture, a few references that really did not make sense out of context, and Greg with is head in his hand & Alex saying “well done for getting through that”.
The image was a cartoon of Captain America giving oral pleasure to Wolverine. I’m just hoping that at some point in the future C4 will be brave enough to put on a late night “best bits” of Task Master where some of the material around that gets shown, as it was incredibly funny.
Chained Rows, Migrated Rows, Row Pieces – The Basics October 11, 2022
Posted by mwidlake in Architecture.Tags: internals, performance, SQL
add a comment
For #JoelKallmanDay I wanted to go back to basics and remind people what Chained & Migrated rows are, and something about row pieces.

First, let’s review how an oracle block is structured. All tables and indexes are made of blocks and they are (by default) all the same size in a given database and the size is stated when you create the database. Blocks are usually 8K (the default), less often 16K and rarely can also be 2K, 4K, or 32K in size. If you want to use a block size other than 8K or 16K, please have a very good, proven reason why before doing so. You can create tablespaces with a block size different to the one stated at database creation, but again you should only do this if you have a very good, proven reason. And I mean a VERY good reason for this one!
(If you have gone the whole CDB/PDB route then PDBs have the same block size as the CDB. You *can* plug in PDBs with different block sizes but check out Mike Deitrich’s post on this first).
At the “top” of the block is the block header, which includes information and access control structures for the rows in the block. Unless you are using Direct Insert, rows are actually inserted from the bottom of the block” upwards, until there is only PCTFREE space available. This is the free space left to cope with row updates and defaults to 10%. PCTFREE is hardly changed these days, which is a shame as it can be very useful to change it for some tables – but that is a different topic.
Why would you use 16K rather than the default of 8K? it is usually used for Data Warehouse database or other database holding long rows. You will generally waste less space within the blocks and avoid row chaining (see later) by having larger blocks, but if you have short rows and an OLTP type database (where you read lots of individual rows) then 16K will be more wasteful of your buffer cache in the SGA and make less efficient use of that memory.

In the above, row 103 is updated, making the row longer. All the rows are packed together so to do this Oracle can do one of two things. In (1) there is enough space at the “top” of the block to hold the whole row, so it is simply moved there and the pointers in the header updated. If there is not enough space in the “top” of the block but there is within the whole block (2), then Oracle moves Row 3 to the “top” of the block and shuffles the rest.

However, if you update a row and there is not enough frees space in the block, what does Oracle do? It Migrates the row. It leaves the row header in the original location but that simply holds a pointer (a ROWID) to the new location of the row – which could be in a block a long way away from the original row, even in a different file of the tablespace. All the columns for the row are moved to this new location. As you are changing two blocks there will be even more REDO generated than if the updated row was contained in the PCTFREE area.
Why does Oracle leave the header in place and simply point to the new row location? Well, if the ROWID for the row changes (as it would if the block it is in changes) then if there any indexes referencing that column, those index entries would need to be changed. Also any internal-to-oracle use of ROWIDs would need to be managed. That is extra work for the database to do and it will take more time. Usually people want updates to happen as quickly as possible.
The impact of this is that if you select that row via eg an index, Oracle will find the row header and have to do a second single block read to get the actual row. That’s more (possibly physical) IO and two blocks in the buffer cache not one. So it is slower. Lot s and lots of row migration can slow down eg index ranges scans considerably.
The impact on full table scans of a simple Migrated row is pretty much zero. Oracle is scanning the full table, the actual row will be found in due course no matter where it is in the table (or partition). The header is simply thrown away.
(Note, if you have enabled ROW MOVEMENT for the table then the whole row may be moved and the relevant indexes/internal rowid references updated – but that’s an advanced topic).
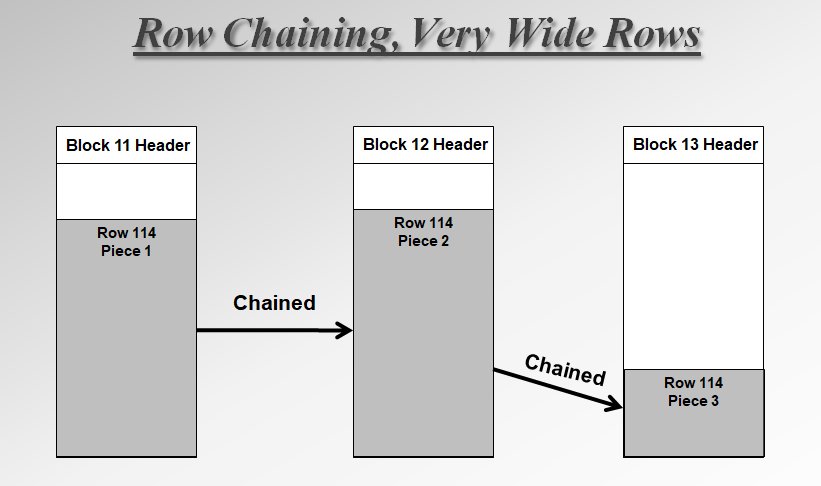
Row chaining is where a row is to wide to fit into a single block. In this case Oracle has no choice but to create several ROW PIECES. In reality every row consists of a header and ROW PIECE but there is only one and it is the ROW PIECE that is migrated with migrate rows. If the row is larger than the block then the row header and the first piece is put in the first available block. If the row is being created large then the next piece(s) are usually put in the following blocks.
Of course, the row could be absolutely massive and chained over many, many blocks. This is generally an indication that the table design and the physical implementation of the database has not been thought about enough and you should either learn enough to sort it out yourself or find someone who can help you with that, it could well help make your database run more efficiently. I’m retired, don’t come and ask me.
You can easily see that if you are reading this single row, for example via an index lookup, then Oracle is going to have to read as many blocks as the row spans. That’s more IO. This won’t happen if all the columns you want are in the first row piece though – Oracle will stop working through the row pieces once it has all the columns it needs.
This sort of row chaining where the row pieces are in contiguous blocks is not much of an issue during FTS as Oracle will stitch the pieces together in memory.
Of course, if you have updated the row to make it too large to fit in a block, your row may not only be chained but migrated, and the row pieces may not be contiguous, especially if you updated the row over several statements/period of time.

There can be even worse issues that come with tables with over 255 columns, but that would be for another blog.
Friday Philosophy – Solving Simple Problems By Asking The One Key Question. June 17, 2022
Posted by mwidlake in Friday Philosophy, performance.Tags: behaviour, performance
add a comment
For many of us solving problems is a large part of our working life in IT. This is especially true when it comes to getting features of a product to do what it is supposed to do or even making a bit of hardware work the way it should. And, if it is a printer, work in any way at all! Often the solution is simple but we ask ourselves the wrong question. I’m going to use this pair of garden secateurs as an example of this. Trust me, go with me on this.

I’ve had these secateurs for many years. For the first few years these secateurs worked wonderfully, but in the last 2 years they have not been working so well. They just don’t cut all the way through stems & small branches, you have to almost pull the piece off that you want to smoothly cut away. I was having to squeeze the handles harder and harder to complete the cut. And now it seemed to make no difference how hard I squeezed, they would not cut cleanly. This is like steadily increasing the size of the SGA to improve query performance, getting some initial gains and then nothing more.
The trick with any such cutting device is to keep the blade sharp, and I do. A few strokes with a needle file every few months keeps the blade sharp. The other issue with an anvil-type pair of secateurs like this is to keep the anvil, the flat area the blade comes down onto, clean and the little central gap clear. The blade closes down on the anvil and the thin gap allows the blade to *just* drop below the main face of the anvil and cleanly cut the stem. This is like the regular maintenance you do on a computer system, like cycling out redundant data or ensuring there are no accounts for staff who have left or rebuilding all your indexes ( 😀 ).


Only, no matter how much I sharpened the blade or cleaned out the anvil the secateurs would not make a clean cut. Ahh, I know. If you look at the above pictures you will see on the blade that the area closest in to the pivot is silver, it is where most of the wear is. Had the blade worn back into a curve so that the key part of the blade was not cutting all the way through? I used a flat piece of metal and checked the blade. Well, the far end was a little proud so I worked on it with the file and got the whole blade totally flat and sharp along the whole length. It was sharp enough so that when I pulled garden twine over the blade it cut straight through with ease.
But they still would not cleanly cut through a stem. I oiled the pivot, for no reason other than blind hope (just like changing configuration parameters for something when you really know those parameters have nothing to do with the problem). I sharpened the blade again (I rebuilt my indexes again). The blade was wickedly sharp, it was flat, the anvil was clean, these secateurs had always worked so well. So I asked the question. Or, more accurately, shouted it at the offending thing:
Why wasn’t *IT* working?!?!!
And that is the wrong question. But it’s usually our attitude to any piece of software or hardware that is not doing what it should. We beat the desk and swear and shout “why won’t you work you piece of crap!!!”
At this point you need to stop and ask a subtly different question:
What is it I don’t understand?!???
The two questions are similar but the key thing is they come from different directions. When you are screaming at the unresponsive printer or swearing about the SQL hint having no effect, your mind-set is that the thing is broken or has a bug or is in some other way not doing what it should. It’s the printer’s fault. The manual is wrong on setting up the feature. This thing is not doing what it should.
Well, yes it is not doing the required thing – but given other people can get the feature to work or the printer was working last week, the problem is unlikely to be there. The problem is actually that I am not understanding something. And it could be very fundamental, so ask the most basic things first. For the printer to print something it needs to be on and I need to send the file to it. Is it on! OK, maybe not that basic, but are you sending the file to the right printer?
Getting back to my example hardware, the blade is sharp enough to cut, the face it is cutting onto is clean, there is no issue with the pivot. What does it need to *do* to cut? The blade needs to come down on the anvil. I closed the secateurs and held them up to the light.

Ahhh, there is a gap! If I squeezed really hard the gap would shrink, but not completely close. The problem is not the blade, it is not the anvil, it is something else that is stopping the two coming together. The problem is elsewhere. And it is simple. And this is often how it is with software & computers. Yes, sometime the problems are very complex or have several confounding factors, but when you are trying to get something to just work, the problem is usually one of missing something obvious, which is usually being impacted by a component you are not currently swearing at.
This is just like last time my printer would not respond to requests to print from my laptop. I’d checked “everything”, swore at the printer, turned it off and on a few times, kicked the cat, sacrificed a small child to the printer Gods. I stopped and I did the “what do I not understand” thing. It turned out that due to a brief power outage a few days earlier my laptop was connecting to the internet via my neighbour’s router not mine (we have a mutual agreement to share due to the connection issues of living in a field and that we use different service providers). The printer and the laptop were not on the same network.


If you look at the secateurs in full you will notice that between the handles there are two plastic lugs that come together. I’m guessing they stop you squeezing the blade deep into the anvil, potentially damaging both blade and anvil. Over the years of sharpening I had worn away the blade enough that these plastic lugs were now preventing the blade and anvil coming together. Especially as, due to my frustration, I had given the blade a really thorough sharpening. That’s why I had been having to squeeze the handles harder & harder until eventually no effort would get a clean cut. I got that needle file out and reduced those lugs by a millimetre or so. The blade now closes on the anvil and, being about as sharp as it has ever been, they cut wonderfully. The solution was wonderfully simple and it took me all of 2 minutes to implement once I had worked it out.
With my first “increasing SGA” example, I was squeezing hard/giving the database a larger buffer cache, and that helped, but the real issue was the sorts were spilling to disc. I needed to increase the PGA (or process less data).

You see, it was not that the secateurs were maliciously working against me or that the components that usually needs some maintenance needed it. It was that I was not understanding something – something very simple & fundamental it turns out. Rather than repeatedly doing the maintenance steps that had worked before but now were not, I needed to stop doing what was no longer working and ask what had changed.
When you are solving problems and it’s got to the swearing stage, it’s time to walk away for 5 minutes, have a cup of tea, and then come back and ask yourself “what do I not understand?”. Best still, do this right at the start. Though to be fair I’m not very good at that, I always get to the swearing stage before I decided to question my understanding.
Especially with printers. I bloody hate printers. Printers are sentient and out to get you.
Friday Philosophy – When Not To Tune! Or Maybe You Should? May 20, 2022
Posted by mwidlake in Friday Philosophy, performance.Tags: performance
add a comment
This week there was an interesting discussion on Twitter between myself, Andy Sayer, Peter Nosko, and several others, on when you do performance tuning. It was started by Andy tweeting the below.

As a general rule, I am absolutely in agreement with this statement and it is something I have been saying in presentations and courses for years. You tune when there is a business need to do so. As Andy says, if a batch process is running to completion in the timeframe available to it, then spending your effort on tuning it up is of no real benefit to the company. The company pays your salary and you have other things to do, so you are in fact wasting their money doing so.
Please note – I said “as a general rule“. There are caveats, exceptions to this rule as I alluded to in my reply-in-agreement tweet:

I cite “Compulsive Tuning Disorder” in my tweet. This is a phrase that has been kicking about for many years, I think it was coined by Gaja Krishna Vaidyanatha. It means someone who, once they have sped up some SQL or code, cannot let it lie and has to keep trying and trying and trying to make it faster. I think anyone who has done a fair bit of performance tuning has suffered from CTD at some point, I know I have. I remember being asked to get a management report that took over an hour to run down to a few minutes, so they could get the output when asked. I got it down to a couple of minutes. But I *knew* I could make it faster to I worked on it and worked on it and I got it down to under 5 seconds.
The business did not need it to run in 5 seconds, they just needed to be able to send the report to the requester within a few minutes of the request (they were not hanging on the phone desperate for this, the manager just wanted it before they forgot they had asked for it). All that the added effort I spent resulted in was a personal sense of achievement and my ability to humble-brag about how much I had sped it up. And my boss being really, very annoyed I had wasted time on it (which is why it sticks out in my mind).
However, there are some very valid reasons for tuning beyond what I’ll call the First Order requirement of satisfying an immediate business need of getting whatever needs to run to run in the time window required. And a couple of these I had not really thought about until the twitter discussion. So here are some of the Second Order reasons for tuning.
1 Freeing Up Resource
All the time that batch job is running for hours it is almost certainly using up resources. If parallel processing is being used (and on any Exadata or similar system it almost certainly is, unless you took steps to prevent it) that could be a lot of CPU, Memory, IO bandwidth, even network. The job might be holding locks or latches. The chances are very high that the 4 hour batch process you are looking at is not the only thing running on the system.
If there other are things running at the same time where there would be a business benefit to them running quicker or they are being impacted by those locks, it could be that tuning those other things would take more effort (or even not be possible) compared to the 4 hour job. So tuning the four hour job releases resource or removes contention.
I had an extreme example of this when some id… IT manager decided to shift another database application on to our server, but the other application was so badly designed it took up all available resource. The quick win was to add some critical indexes to the other application whilst we “negotiated” about it’s removal.
2 Future Proofing
Sometimes something needs tuning to complete in line with a Service Level Agreement, say complete in 10 seconds. You get it done, only to have to repeat the exercise in a few months as the piece of code in question has slowed down again. And you realise that as (for example) data volumes increase this is likely to be a recurring task.
It may well be worth putting in the extra effort to not only get the code to sub-10-seconds but significantly less than that. Better still, spend extra effort to solve the issue causing the code to slow down as more data is present. After all, if you get the code down to 1 second and it goes up to 5, even though it is meeting the SLA the user may well still be unhappy – “Why does this screen get slow, then speeds up for a few months, only to slow down again! At the start of the year it was appearing immediately, now it takes forevvveeeeer!”. End users MUCH prefer stable, average performance than toggling between very fast and simply fast.
3 Impacting Other Time Zones
This is sort-of the first point about resource, but it can be missed as the people being impacted by your overnight batch are in a different part of the globe. When you and the rest of your office are asleep – in America let’s say – Other users are in Asia, having a rubbish time with the system being dog slow. Depending on the culture or structure of your organisation, you may not hear the complaints from people in other countries or parts of the wider company.
4 Pre-emptive Tuning
I’m not so convinced by this one. The idea is that you look for the “most demanding” code (be it long-running, resource usage, or execution rate) and tune it up, so that you prevent any issues occurring in the future. This is not the earlier Freeing Up Resources argument, nothing is really slow at the time you do this. I think it is more pandering to someone’s CTD. I think any such effort would be far better spent trying to design in performance to a new part of the application.
5 Restart/Recovery
I’d not really thought clearly about this one until Peter Nosko highlighted it. If that four hour batch that was causing no issues fails and has to be re-run, then the extra four house could have a serious business impact.
Is this a performance issue or is it a Disaster Recovery consideration? Actually it does not matter what you label it, it is a potential threat to the business. The solution to it is far more complex and depends on several things, one of which is can the batch be partially recovered or not?
When I design long running processes I always consider recovery/restart. If it is a one-off job such as initial data take-on I don’t put much effort into it. It works or it fails and your recovery is to go back to the original system or something. If it a regular data load of 100’s of GB of critical data, that process has to be gold plated.
I design such systems so that they load data in batches in loops. The data is marked with the loop ID and ascending primary key values are logged, and the instrumentation records which stage it has got to. If someone kicks the plug out the server or the batch hits a critical error, you can restart it, it will clean up any partially completed loops and then start from after the last completed batch. It takes a lot more effort to develop but the pay-back can be huge. I worked on one project that was so out of control that the structure of the data was not really known and would change over time, so the batch would fail all the bloody time, and I would have to re-run it once someone had fixed the latest issue . The ability to restart with little lost time was a god-send to me – and the business, not that they really noticed.
Simply tuning up the batch run to complete more quickly, as Peter suggests, so it can be blown away and repeated several times is a pragmatic alternative. NB Peter also said he does something similar to what I describe above.
6 Freeing Up Cloud Resource
Again, I had not thought of this before but Thomas Teske made the point that if your system is living in the cloud and you are charged by resource usage, you may save money by tuning up anything that uses a lot of resource. You are not satisfying a First Order business need of getting things done in time but you are satisfying a First Order business need of reducing cost
7 Learning How To Tune
I think this is greatly under-rated as a reason to tune something, and even indulge in a little CTD even when the First Order business need has been met. It does not matter how much you read stuff by tuning experts, you are only going to properly learn how to performance tune, and especially tune in your specific environment, by practice. By doing it. The philosophy of performance tuning is of course a massive topic, but by looking at why things take time to run, coming up with potential solutions, and testing them, you will become really pretty good at it. And thus better at your job and more useful to your employer.
Of course, this increase in your skills may not be a First, Second, or even Third Order business need of your employer, but it could well help you change employer 😀 .
8 Integration Testing
Again highlighted by Peter Nosko, we should all be doing integrated, continuous testing, or at least something as close to that as possible. Testing a four hour batch run takes, err, more time than a 15 minute batch run. For the sake of integration testing you want to get that time down.
But, as I point out..

{joke – don’t take this tweet seriously}
As I think you can see, there are many reasons why it might be beneficial to tune up something where the First Order business need is being met, but the Second Order benefits are significant. I am sure there are some other benefits to speeding up that batch job that finishes at 4am.
I’ll finish with one observation, made by a couple of other people on the Twitter discussion (such as Nenad Noveljic). If you fix the First Order issue, when management is screaming and cry and offering a bonus to whoever does it (like that ever happens) you get noticed. Fixing Second Order issues they did not see, especially as they now may not even occur, is going to get you no reward at all.


Finally Getting Broadband – Via 4G! (cable-free, fast-ish internet) February 15, 2021
Posted by mwidlake in Architecture, Hardware, off-topic, Private Life.Tags: Architecture, hardware, performance, private
2 comments
I live in a field. Well, I live in a house, but it and a few other houses make up a tiny hamlet surrounded by fields. My back garden is itself a small field. It’s nice to live surrounded by countryside, but one of the drawbacks of this rural idyll is our internet connection. Our house is connected to the World Wide Web by a copper telephone line (via a British Telecom service), and it’s not a very good copper telephone line either. I joke that wet, hairy string would be just as useful. Our connection speed is, at best, about 5Mbps download and 0.4Mbps upload. That is not a typo – nought point four megabits a second. My dual ISDN line back in 2003 could just about manage that. At busy times it’s worse – a lot worse – as all the houses in our hamlet contend for whatever bandwidth we have back to civilisation. Evenings & weekends it has almost become a not-service. It is not broadband, it’s narrowband. I pay £23 a month for the wire charge & unlimited calls, another £25 a month for the calls beyond “unlimited” (yeah, tell me) and £30 a month for the narrowband connection. Ouch!

It’s all fields and very little infrastructure…

Good BT service.
My neighbours have complained to BT about our internet speed many times over the years and I did also. I was told (and I paraphrase) “you are at the end of a long piece of old copper-wire-based technology and there are not enough people living there for us to care about, so it is not changing”. Which to me utterly sums up my 30 or so years experience of British Telecom, a company I loath with a passion. I asked if I could get a discount for such a shit service and was told I was on their cheapest deal already. “Would I get better service if I paid more?” No. Well, at least they were honest about that.
About 2 years ago a company called Gigaclear came down the road to our little, rural hamlet. They are being paid a lot of money by Essex county council to lay fibre cable to rural locations all over the district. This raised our hopes. Gigaclear dug channels, lay down the ducting, put a green telecommunications box in place by “Joe on the Donkey” (this is the real name of a neighbour’s house) – and went away. They’ve been back a few times since, but the promised super-mega-fast fibre broadband service they touted has not come to fruition. The last two visits have been to check out why they can’t connect anyone. It might partly be that one pair could not even understand that the green box 100 meters away is probably the one that is supposed to service our house, not the one way across two fields that they have not dug a channel from.
Bad Weekend BT service
I first realised there was another solution when, forced by evenings & weekends when download speeds dropped to below 1Mbps, I started using my iPhone as a hotspot for my laptop. 5/0.4Mpps was replaced by 15/2.0Mbps. I was soon using my phone to upload pictures to social media and the charity I foster cats for, plus for video conferencing for work & social purposes. If my mobile phone was giving me better connection speed, why in hell was I using an expensive & slower connection from my physical telephone line? One problem was I only have so much download allowance on my mobile phone (10GB). The other was you need to keep the mobile by the computer to tether it. It was not a mobile anymore!
I was then chatting to a neighbour and he said he’d tried a relative’s 4G broadband from EE – EE is about the only phone network we can get a decent signal with here and we use them for our mobile phones – and he was pleasantly surprised at the speed. He said it was expensive though…
As a result of this chat I did a quick check on the EE website. A 4G EE broadband device (basically a box with the electronics for a mobile phone and a router in it) would be cheaper than my current BT solution! £35 a month, no up-front fee, and their advertising blurb claimed 31Mbps on average “in some places”. I had no expectation of getting anything near that sales-pitch speed, but repeated speed test on my EE mobile phone was confirming 15 Mbps download and 2 Mbps upload usually, much better than the BT landline. And the offerings of Gigaclear, should they ever plumb us in, was for 30Mbps for a similar cost to EE 4G broadband, and 100Mbps if you spent more spondoolies. All in all, EE seemed not that expensive really and, as I said, cheaper than sod-all bandwidth with BT!
The last thing I checked was if you could get a physical EE 4G signal booster if your signal was poor. Yes, you can, but from 3rd party companies for about £250-£400. Our EE signal in Widlake Towers is better than any other mobile phone operator but it is never an all-bars signal.
The Change to 4G, cable-free Broadband
I decided it was worth a risk. All I wanted was the speed my iPhone was getting and, if it was poorer, a one-off spend of maybe £300 would help matters. I ordered an EE 4G router and 200GB of data a month. Why so much data? Well, I had never exceeded my 10GB data a month on my mobile phone, I am not what you could call a big data user – I do not download films or live stream stuff. But my connection speed had been so bloody awful for so long I had never even dreamed of downloading 1/2 hour TV programs, let alone whole movies! Maybe I might with a better connection. And I was about to start running training courses for a client. I figured I would bet on the safe side.
My EE 4G router turned up the next day, I was so excited!
It was broken. It would get the 4G signal no trouble but it’s wifi service was unstable, it shut down under load. It was so annoying as for 10 minutes I had FORTY Mbps download and FIFTEEN Mbps upload performance! I count this as mental cruelty, to let me see the sunny uplands of normal 1st world internet access but to then immediately remove it from me…
It was clearly a faulty unit so I was straight on to EE. It took over an hour and a half to contact & talk through the issue with EE but, to be fair, they have a process to go through and they have to make sure the customer is not doing something daft like keeping the router in a basement, and they sent me a replacement unit the very next day.

This is more like it!
It arrived. I plugged it in. It worked. It’s was great! The bandwidth was an order of magnitude better than the old BT router over the fixed telephone cable. Not only that, it also far exceeded both what I had got via my phone and also the estimates of EE. I got over 60Mbps download on average and often above 70 Mbps. The highest I have seen so far is 98Mbps. Upload averages around 14Mpbs and has gone up to 30 Mbps at times – but I have to say I see the peak upload when download is a little depressed. On average I am now getting consistently over 60Mbps download and 10Mbps upload speeds, though sometimes when the local network is busy (mid workday afternoon) I see a little less. “Peak performance” is weekend and evening times, I get fantastic performance, maybe as business users in the area are quieter and few domestic clients are using the 4G network.
So, over 60Mbps download and 10Mbps upload average and sometimes more – I’ll take that! more than 10 times faster download and, well, 30-50 times faster upload then BT over tired copper.
It’s utterly transformed my online experience. I can honestly say that when I see slow internet performance on web pages now I am just as inclined to blame the remote site as my connection. And I can upload pictures & emails in a way I have never been able to before. Until now I was notable to put up short videos of our foster cats to the charity website unless I did it on my phone in the garden, and that was hit-and-miss. Now I can just chuck videos over to them and not worry about it. For me it is a game changer.
My 4G Choice

In the window, catching rays – 4G rays
I had little choice but to go for EE as no other mobile phone company has decent coverage in my area. You may also have only 1 choice but, it you live in an area where many 4G services are available (i.e. you live in a place where other people live!) then look into which is best – not just for speed/cost but also customer service. Many companies are offering wireless 4 and 5G services. Personally I would stick to 4G as 5G is still shiny and new enough to come with a price hike for not-a-lot more total throughput. I’ve always been really pleased with EE customer service. For years I’ve popped over to one of the two local-ish EE shops whenever I have needed to change something or had a problem and they always sort me out quickly. Not only that, on a couple of occasions I’ve suggested I go for a more expensive plan (say to get more roaming data allowance) and they have looked at my historic usages – “Mate, you’ve never been even close to the smaller plan, save yourself £10 a month and take the cheaper one. You can always upgrade”.
I went for EE’s standard 4G Home Router as the only difference I could see with it and their 4G Home Router 2 was the Home Router 2 supported 64 devices not 32, for an extra £50 up front.. Between us Mrs Widlake and I have fewer than 10 devices, let alone over 32…. At the time of writing there is no initial charge for the 4G Home Router, just a £35-£55 monthly charge depending on what data allowance you want £35=100GB, you get an extra 100GB for each additional £5 up to 500GB but then at £55 it becomes unlimited. You can choose between 18 month contract or no contract and an up-front fee, but go look at the website for details, it will have changed by the time you look (I know this as they have introduced a 5G home router between the time I started this blog post an ended it! But I have no 5G signal so of no consideration for me).

In line of sight of the study window
Initially I had the EE 4G home router in the main room of the house so I could fiddle with it if needed, but I soon moved it upstairs to a bedroom where prior tests had shown I got a better 4G signal. (You want as little in the way of building materials and geography between you and the 4G mast, so upstairs by a window is ideal. And in my house the top floor where I put the router is made of wood, straw, mud, & horse shit. Other parts have fully insulated plasterboard which includes a thin metal foil layer to both reflect heat and, unfortunately, block electromagnetic radiation).
Spreading The Network
Another consideration for me was allowing the wifi signal to get to the study. The study is above the garage, a structure covered in black clapperboard which is strangely attached to the neighbour’s house (this is the sort of thing you get with properties hundreds of years old – things just got built). A few years ago when we had the study/garage rebuilt to modern standards we got another company to provide telephone services to the study, to see if it was better than BT. It was. A bit. And it still is. But that company is now part of BT (as is EE to be fair) and is slower than my mobile phone. If the new router reached the study we could stop using BT AND we could stop using this backup supplier (which was cheaper than BT but more limited in some respects). With line-of-sight I hoped the wifi would reach the study. It did – but it was right at the range limit and the signal would drop :-(. If you moved your laptop or tablet away from the window and clear line-of-site, you lost the Wifi signal from the new 4G broadband router.

I see you (just) router
Well, I had a possible solution to this too.
There are many wifi extenders on the market at many prices, some just use wifi and some use your power cables and others create a mesh. If 30 years in I.T. have taught me anything it is that there is something deficient in my head that means I personally have no affinity for networks. I need simple. I knew I could not use a power cable solution. With these you plug one device in a socket and it communicates over your domestic power lines to a second plugged-in device which provides a wifi service. For historical reasons my study is on a different power circuit to the house, I doubt it would work. I did not want to go to Mesh as I felt (based on experience) I would fuck it up. I just wanted a simple, single WiFi extender.
After a few hours on the internet I came to the conclusion that there was a solution, a relatively old device (first sold in 2016) that might be what I wanted. A TP Link RE450, also known as an AC1750. It was simple and excelled at having a long range. I ordered one for £50 quid.
It came and, following the simple instructions and maybe half an hour of my part-time attention, I had it working and connecting to both the 5 and 2.4 GHz networks of my EE 4G broadband router. I moved the TP Link RE450 over to the study and plugged it in so it had line-of-site to my EE 4G router. The connection light flashed blue and red, which suggested it was not happy – but I worked out that it was happy with the 2.4Ghz connection but not the 5Ghz one. It was right on the edge of it’s range. A bit of fiddling of orientation (hat tip to Mrs W who realised it was better on it’s side) over 2 days, including moving the router a whole 30cm closer, and now both are happy.
The end result is I now have access to the 4G EE broadband router in the study & garage at about 20Mbps download and 12 Mbps upload. I think the limit is the TP Link to EE router connection, which is just down to distance. Bottom line, I now have access to the internet from every part of my house and separate study, and the whole front garden, and the edge of the field opposite the house, and some of the back garden, at speeds substantially faster than my old landline.
British Telecom will be getting a cancellation notice from me by the end of the month (I need to change some email addresses) and the third party service to the study will also be terminated. I will replace a service from BT that was costing me £80 a month and another that was £30 a month with just one at £40 a month, which gives me a much, much better service.
That feels good.
Latest speed test? Done as I completed this post, I recorded 77Mbps download & 30Mbps upload, which I am incredibly pleased with. I don’t expect to get that all the time though.

Speed test the morning I posted this. It will do 🙂
Friday Philosophy – Explaining How Performance Tuning Is Not Magic? March 9, 2018
Posted by mwidlake in Friday Philosophy, performance, SQL.Tags: cost, explain plan, perception, performance, SQL
8 comments
Solving performance issues is not magic. Oh, I’m not saying it is always easy and I am not saying that you do not need both a lot of knowledge and also creativity. But it is not a dark art, at least not on Oracle systems where we have a wealth of tools and instrumentation to help us. But it can feel like that, especially when you lack experience of systematically solving performance issues.

SQL statement be fast!
I recently spent a couple of days with a client discussing how you solve performance issues and I am preparing a talk on exactly that for the up-coming OUG Ireland conference on the 22nd-23rd March. The guys I was talking to at the client are very, very capable production DBAs, but traditionally the developers at their site initially look at any performance issues. If they think it is the database but not something they can fix, they throw it over the fence at the DBAs. It’s not always the database of course and, if it was a simple fix (missing index, obviouosly inefficient query), then the developers fixed it. So these two guys are expected to only solve the more difficult issues. That’s not really fair as, if you are not practising on the simple problems how are you supposed to gain the experience and confidence to solve the harder ones?
Anyway, a part of the discussion was about Explain Plans. What does the COST mean in the plan, they asked? They saw it as some number that in an undefined way gave an indication of how expensive the step in the plan was, but they could not link it back to anything solid that made sense to them. It looked like a magically produced number that was sometimes very, very wrong. Like most (good) technical people, they want to know the details of things and how they work, they don’t want to simple accept something as working.
So I took them through some simple examples of plans and of how the COST is just a result of simple maths estimating the number of IOs needed to satisfy the step.
I won’t go into the full details here but have a look at the below, this is how I started:

I explained how you read “down” the slope of plan to the end (so step 3) and then worked back up the slope. So the first thing Oracle does is the index range scan. I showed them the BLEVEL of the index, the number of blocks per indexed value and why Oracle knew it would, on average, need 3 IOs to get the leaf block entries for the provided “DOB=to_date(’08-OCT-1934′,’DD-MON-YYYY’)”. Each DOB matched, on average, 20 rows. So the cost of step 3 was passed up to the step 2 of accessing the table rows. This would be done 20 times so the cost was 20+3. 23.
OK, they could accept that, it made sense. So let’s extend it…
I took the original query against PERSON for a given DOB and now joined it to a second table PERSON_NAME. Why is not important, it’s just a demonstration of a simple table join:

Now I explained that as you work “back up the slope of the plan” from the first, most indented step (so from step 5 to 4 to 3) at 3 there is a nested loop joining the rows passed to step 4 to the step in line below it, i.e. step 6. They had already seen steps 5 and 4 in our first example, Oracle is expecting to get 20 rows for a cost of 23. Look at line 4. And for each of those 20 rows, it will do a range scan of the index in step 6 and for each row it finds in the index, collect rows from the joined table in step 7.
So for each of the 20 original rows it does a scan of an index on the joined table for a cost of 2 (I showed the stats to them how this cost is calculated) and expects on average to find 5 matching rows so it needs to do 5 IOs to the PERSON_NAME to get those rows. Add that together and that cost of 7 is done 20 times. 7*20 is 140, plus the 23 from the orginal scan of the PERSON table, the whole COST is… 163.
Light bulbs came on and they got it! My job here is done.
But it was not. I then went on to explain how it is now hard to get such a simple example. This one is, I think, from an early version of Oracle 11. I told them how histograms on a column will make the estimated cardinality (number of records per given value for a column) more accurate, but harder to work out. I showed them how the cost of a unique index scan is reduced by 1. I explained how Oracle was blind to the correlation of column values unless you took steps to tell the optimiser about it (you know, how for a given value of car manufacturer there will be only a few values of car model, the two values are related)…
Worry was creeping back into their faces. “so it is simple mathematics – but the rules are complex? It’s complex simple mathematics?!?” Err, yes. And with 11 and 12 Oracle will use various methods to spot when the simple, complex mathematics does not match reality and will swap plans as a result…
I think I lost them at that point. Especially when they asked about the SQL Profiles and how they modified Costs… Baselines controlling how plans are used… Bind variables…
That is a real problem with Oracle Performance tuning now. Even something as simple as COST is based on a lot of rules, factors and clever tricks. And they are not the only things controlling which plan is executed anymore.
So I took a step back.
I told them to accept that the COST is really, honestly based on maths, and the expected number of ROWS is too. But the actual, specific values could be hard to totally justify. And it is when the estimated COST and (possibly more importantly) the estimated ROWS goes wrong you have problems. So look out for ROWS of 1 (or at least very low) in a plan for a statement that takes more than a few milliseconds. And for very, very large COSTS/ROWS in the millions or more. And what really helps id if you get the ACTUAL ROWS as opposed to the ESTIMATED RIWS. Where there is a significant difference, concentrate your focus there. Of course, getting the ACTUAL ROWS is not always easy and is for a later (and properly technical) post.
So, they asked, if they could not get the actual ROWS and there were no 1’s or millions’s in the plan ROWS/COSTS? How did they know where to concentrate? “Well, you just get a feel for it… do the costs feel reasonable?…”
Damn – I’m not sure I really delivered on my aim of proving Performance Tuning is science and not magic.
Any pointers anyone?
(Update – Vbarun made a comment that made me realise I had messed up the end of this post, I was talking about estimated ROWS and still had the words COST there. Now fixed. And the other thing I was hoping someone was going to suggest as a pointer was – to split the query down to individual tables & two-table joins and *check* how many rows you get back with the where predicates being used. It takes some time but it shows you where the estimates are going wrong.)
Overloaded Indexes (for ODC Appreciation Day) October 10, 2017
Posted by mwidlake in database design, development, performance, SQL.Tags: index organized tables, performance, SQL
add a comment
ODC Appreciation Day is an idea that Tim Hall (aka Oracle-Base) came up with, to show out appreciation for the Oracle Technology Network (OTN)/Oracle Developer Community.

Fig 1 This is an efficient range scan
I want to show my support but rather than mention an Oracle “feature” I particularly like I’d like to mention a “trick” that I (and many others) often employ to help performance. That trick is Overloaded Indexes.
We can all appreciate that accessing data in a table via an index is a very good thing to do when we want just the few records for a given index key from the thousands or millions of rows in the table. As an example, we are looking up all the records for someone and we know their first name, last name and date of birth – a very common occurrence in things like hospital or billing systems. So our PERSON table has an index on those three columns. Oracle will read the root block of the index, read the one relevant block in each of the branch levels for the key, find all of the leaf block entries for that key – and then collect the relevant rows from the table. Fig 1 shows how we think of this working. i.e. most of the records we want to find will be close together in the table.
Actually, a lot of people who just “use” the Oracle database as a store of information sort-of think this is how an index always works. It efficiently identifies the rows that you want and that is the end of it. If the index is on the value(s) you are looking up rows for (say LAST_NAME, FIRST_NAME, DATE_OF_BIRTH) the index is ideal and that is as good as it gets.

Fig 2 – a more usual, less efficient index range scan
But in reality, the index lookup is often far less efficient than this and is more like fig 2. Working down the index structure to get all of the required index entries is exactly the same, but the rows you want are scattered all over the table. Oracle has to fetch many table blocks to get your data, maybe as many blocks as there records to be found. This is far from efficient.
So what can you do about this? You already have the “perfect” index, on LAST_NAME, FIRST_NAME, DATE_OF_BIRTH, the values you are looking up. Maybe you could add another column to the index to avoid those situations where there are many people with the same name and date of birth. But you may not have that extra information or it is simply not possible to identify the values in the table any more accurately, you really do need all the rows scattered though that table for the given search key.
There are “architectural” things you can do such as create the table as an Index Organised Table (see my little set of blogs about them starting here). You can also use various methods to group the relevant rows together in the table. But all of those methods are Big Impact. You need to recreate the table or plan for this eventuality up-front when you design the system.
But there is a very specific, easy thing you can do to address this particular problem, for the SQL statement you need to speed up. You can add all the columns your query needs into the index. This is an Overloaded Index.
An Overloaded Index holds not only the table columns in the WHERE clause but all the columns needed from that table for the query.
Why does this work? Because when Oracle identifies the range of keys for the key (LAST_NAME, FIRST_NAME, DATE_OF_BIRTH) all the other columns it needs are also in those index leaf entries and there is no need to get the rows from the table. All those lookups to the table are avoided. Fig 3 at the end of this article demonstrates this.
However, I’ll give you a real world example I had recently. A client had a SELECT statement something like the below, with the execution plan shown, and it was running too slowly for the business requirements:
SELECT (SUM(NVL(T.TRAN_VALUE_CR,0))-SUM(NVL(T.TRAN_VALUE_DB,0))) ,
COUNT(*)
FROM ACCOUNTS A ,
TRANSACTIONS T
WHERE A.ACC_XYZ_IND =:3
AND A.ACC_ACCOUNT_NO =:1
AND A.ACC_SUBACC_NO =:2
AND T.TRAN_XYZ_IND =A.ACC_XYZ_IND
AND T.TRAN_ACCOUNT_NO =A.ACC_ACCOUNT_NO
AND T.TRAN_SUBACC_NO =A.ACC_SUBACC_NO
AND T.TRAN_P_IND =:4
AND T.TRAN_DLM_DATE >=TO_DATE(:5,'YYYYMMDD')
------------------------------------------------------------
| Operation | Name |
------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | SORT AGGREGATE | |
| 2 | NESTED LOOPS | |
| 3 | NESTED LOOPS | |
|* 4 | INDEX RANGE SCAN | ACC_PRIME |
|* 5 | INDEX RANGE SCAN | TRAN2_3 |
|* 6 | TABLE ACCESS BY LOCAL INDEX ROWID| TRANSACTIONS |
------------------------------------------------------------
Statistics
----------------------------------------------------------
4740 consistent gets
3317 physical reads
The index used on TRANSACTIONS is:
INDEX_NAME TABLE_NAME PSN COL_NAME
---------------------------- ---------------- --- --------------
TRAN2_3 TRANSACTIONS 1 TRAN_ACCOUNT_NO
TRAN2_3 TRANSACTIONS 2 TRAN_SUBACC_NO
TRAN2_3 TRANSACTIONS 3 TRAN_DLM_DATE
The index TRAN2_3 on the TRANSACTION table that you can see being used in the plan was for all the columns being used in the WHERE clause that actually helped identify the TRANSACTION records required – TRAN_ACCOUNT_NO, TRAN_SUBACC_NO and TRAN_DLM_DATE (the TRAN_XYZ_IND and TRAN_P_IND were always the same so “pointless” to index).
I added a new index to the TRANSACTION table. I added a new index rather than change the existing index as we did not want to impact other code and we wanted to be able to drop this new index if there were any unexpected problems. I added all the columns on the TRANSACTION table that were in the SELECT list, were in the the WHERE clauses even though they did not help better identify the rows needed. If there had been TRANSACTION columns in an ORDER BY or windowing clause, I would have added them too. So my index looked like this:
create index TRAN2_FQ on TRANSACTIONS (TRAN_ACCOUNT_NO ,TRAN_SUBACC_NO ,TRAN_DLM_DATE ,TRAN_P_IND ,TRAN_XYZ_IND ,TRAN_VALUE_CR ,TRAN_VALUE_DB)
It is very, very important that the new index holds every column from the TRANSACTION table that the query needs.To prevent accessing the table, all the data the query needs for that table must be in the index.
The query could now satisfy the query by just using the new index, as the below explain plan shows.
----------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | SORT AGGREGATE | |
| 2 | NESTED LOOPS | |
|* 3 | INDEX RANGE SCAN | ACC_PRIME |
|* 4 | INDEX RANGE SCAN | TRAN2_FQ |
----------------------------------------------------
Statistics
----------------------------------------------------
56 consistent gets
52 physical reads
There is now no line in the plan for visiting the table TRANSACTIONS and we are using the new TRAN2_FQ index. The consistent gets and physical reads to satisfy the query have gone down from 4740 and 3317 respectively to 56 and 52. I think that is good enough.
Fig 3 shows what is happening. The new index is effectively a “mini IOT” designed to support the given query.

Fig 3 – Tables? Who needs tables!
There are of course a few caveats. The new index needs to be maintained, which is an overhead on all INSERT/UPDATE/MERGE/DELETE activity on the table. The index will only remove the need to visit the table for queries that are very, very similar to the one it is designed for – ones that use the same rows from the TRANSACTIONS table or a subset of them. If you alter the query you, e.g. select another column from the TRANSACTION table you would need to revisit this overloaded index.
Finally, be careful of modifying existing indexes to overload them to support specific queries. If the index is there to support referential integrity you need to think carefully about this and the modified index may be less efficient for other queries that used the original index (as adding columns to an index make it “wider”).
BTW if you think you recognise this from a recent Oracle Scene article then you would be right. I was pushed for time, I used something I had written before 🙂
Free Webinar – How Oracle Works! September 15, 2017
Posted by mwidlake in Architecture, internals, Knowledge, Presenting.Tags: Architecture, knowledge, performance, Presenting
3 comments
Next Tuesday (19th September) I am doing a free webinar for ProHuddle. It lasts under an hour and is an introduction to how some of the core parts of the Oracle RDBMS work, I call it “The Heart of Oracle: How the Core RDBMS Works”. Yes, I try and explain all of the core Oracle RDBMS in under an hour! I’m told I just about manage it. You can see details of the event and register for it here. I’ve done this talk a few times at conferences now and I really like doing it, partly as it seems to go down so well and people give me good feedback about it (and occasionally bad feedback, but I’ll get on to that).

The idea behind the presentation is not to do the usual “Intro” and list what the main Oracle operating systems processes – SMON, PMON, RECO etc – are or what the various components of the shared memory do. I always found those talks a little boring and they do not really help you understand why Oracle works the way it does when you use it. I aim to explain what redo is, why it is so important, what actually happens when you commit, how data is written to and read from storage to the cache – and what is actually put in the buffer cache. I explain the concept of point-in-time view, how Oracle does it and why it is so fantastic. And a few other bits and pieces.
I’m not trying to explain to people the absolute correct details of what goes on with all these activities that the database does for you. I’m attempting to give people an understanding of the principles so that more advanced topics make more sense and fit together. The talk is, of course, aimed at people who are relatively new to Oracle – students, new DBAS or developers who have never had explained to them why Oracle works the way it does. But I have found that even some very experienced DBA-types have learnt the odd little nugget of information from the talk.
Of course, in an hour there is only so much detail I can go into when covering what is a pretty broad set of topics. And I lie about things. I say things that are not strictly true, that do not apply if more advanced features of Oracle are used, or that ignore a whole bucket full of exceptions. But it’s like teaching astrophysics at school. You first learn about how the Sun is at the centre of the solar system, all the planets & moons revolve around each other due to gravity and the sun is hot due to nuclear fusion. No one mentions how the earth’s orbit varies over thousands and millions of years until you have the basics. Or that GPS satellites have to take into account the theory of relativity to be as accurate as they are. Those finer details are great to learn but they do not change the fundamental principles of planets going around suns and rocks falling out of the sky – and you need to know the simpler overall “story” to slot in the more complex information.

I talk about this picture.
I start off the talk explaining this simplification and I do try to indicate where people will need to dig deeper if they, for example, have Exadata – but with a webinar I am sure people will join late, drop in and out and might miss that. I must remember to keep reminding people I’m ignoring details. And amongst the audience will be people who know enough to spot some of these “simplifications” and I think the occasional person might get upset. Remember I mentioned the bad feedback? I got accosted at a conference once after I had done this talk by a couple of experts, who were really angry with me that I had said something that was not accurate. But they had missed the start of the talk and my warnings of simplification and did not seem to be able to understand that I would have needed half an hour to explain the details of that on thing that they knew – but I had only 50 minutes in total for everything!
As I said, this is the first Webinar I will have done. I am sure it will be strange for me to present with “no audience” and I’m sure I’ll trip up with the pointer and the slides at some point. I usually have some humour in my presentations but that might not work with no crowd feedback and a worldwide audience. We will see. But I am excited about doing it and, if it works, I may well offer to do more.
As a taster, I explain the above diagram. A lot. I mostly just talk about pictures, there will be very few “wordy” slides.
I invite you all to register for the talk – as I said, it is free – and please do spread the word.
Friday Philosophy – Sometime The Solution Has To Not Only Match The Problem But Also… August 4, 2017
Posted by mwidlake in Architecture, development, Friday Philosophy, Perceptions, Programming.Tags: behaviour, perception, performance, system development
3 comments
…The People!
When you design a system for end users, a good designer/developer considers the “UX” – User eXperience. The system has to be acceptable to the end user. This is often expressed as “easy to use” or “fun” or “Quick”. But in reality, the system can fail in all sort of ways but still be a success if the end user gets something out of using it. I’ve said it before and I’ll say it again and again until I give up on this career. In my opinion:
User Acceptance is the number one aim of any I.T. system.
OK, you all know about UX probably. But what about solutions that have no End Users? I’m thinking about when you create a technical solution or fix for an internal system, to be used by fellow I.T. professionals. How many have you considered the skills and temperament of the people who are going to house-keep the solution you create? I suppose I have had opportunity to think about this more than some of you due to how I work:- I’m a consultant who gets called in to fix things and then leave. At times I have chosen a solution that has been influenced by the people who will be looking after it.
I’ll give you an example. At one site that I worked at for about 9 months, I did a lot of work for one system. The developer/systems administrator who looked after the system was…stupid. I don’t really like saying that, we all vary in our skill set, experience, intelligence, *type* of intelligence (I know some people who can speak 3 languages or know a lot about history but could not wire a plug). But this guy really seemed to struggle with logic, cause-and-effect or learning anything new. And I had to help him look after this database application with one main, huge, hulking table. It had to be partitioned, those partitions maintained and the data archived. I implemented the partitioning, I explained partitions to him several times, what was needed to maintain them, where to look in the data dictionary for information. It was like talking to my mum about it. He just seemed not to understand and his efforts to code something to do what needed to be done were woeful.
I knew it was not me, I’ve run enough training sessions and presented so often that I know I can explain myself (Well, I hope so! Maybe I am deluded). He just was not getting it. Maybe he was in the wrong job. So I wrote him a set of SQL-generating scripts to get him going. He kept messing up running them. In the end, I knew I was about to leave and when I did within 3 months the real customer would have a broken system. So I wrote a mini-application in PL/SQL for him to do what needed to be done. And set it to email a central team if it failed. The team he would call when he broke it all again. I also simplified the solution. My original system had some bells and whistles to help with future changes, such as over-riding where new partitions went or how old ones were compressed. I stripped it out to keep it as simple as possible. I altered the solution to suit the person that would run it.
I’ve done something like this a few times over the years. Usually it is more to do with the skill set of the team as opposed to actual ability. I’ve on occasion worked with people who are new to Oracle and my time is limited so, rather than give them a solution written in PL/SQL that none of them know, I have done so with SQL and cookery instructions/shell scripts. It’s not the best solution but it is something they can live with.
More recently I had to look at fixing the performance of some SQL statements. Baselines would have done the job perfectly. However, the team were all Java experts and had no desire at all to learn about database administration. (To be frank, they had no time to learn either, it was the usual situation of them having 75 hours of work each every week as management thought just shouting would get things fixed, not hiring enough people). I strongly suspected that they would forget about the baselines and if they had a problem they would be confused as to what was going on. So I fixed the key SQL statements with a set of hints to force both the overall structure of the execution plans as well as which indexes to use etc – and said over and over and over and over that if they ever changed indexes or migrated to a later version of Oracle, those hints would need reviewing. They were, in effect, part of their code base. A big advantage of the hints was that they would see them in their code and it would remind them what had been done. They seemed happy with that.
My point is, sometimes the “best” solution is not the correct one, even when you are keeping within the walls of the computing department(s). Sometimes you need to think about who you are giving the solution to and change the solution accordingly.

